Before I begin to explain CSRFs we need to understand some facts.
First of all, we have to see how websites usually work when they have a login. Most pages use username/email and password for authentication. In today's world, it's not uncommon for newer sites to support two-step authentication.
Normally we use a login once on a website because it generates on the server side a session which reminds our browser that we are already logged in. Generally, the session has an expiration time and when it expires we have to login again.
After we login, the browser receives some cookies which need to be sent back to the server with every request. As a result, we don’t have to login again after each request, because the cookies have the information which the server requires to identify our session.
This seems to be quite normal, but what happens if we get a direct request to the website where we logged in?
What is CSRF?
The cross-site request forgery (CSRF) is a vulnerability which allows the attacker to get information or to perform unauthorized actions on a site where the victim user is logged in.
No one can access the browser data directly from the remote, so how do they do it?
Let me introduce this through an example, in which Bob can change his email address and his account using this request: example.com/settings/email?change_to=bob@example.com. This is the situation from that point of view:
- Bob logs in to this site: example.com
- Bob gets an email which tells him that big discounts are available in a webshop. He must click on the link for more details.
- Bob clicks on the link and is redirected to a fake website.
- This content is readable in the client source of the fake website which Bob doesn’t see because it is hidden by an external HTML element:
![]() example.com/settings/email?change_to=hacker@gmal.com">
example.com/settings/email?change_to=hacker@gmal.com"> - The request is executed and the result of this is the hacker stealing Bob’s account.
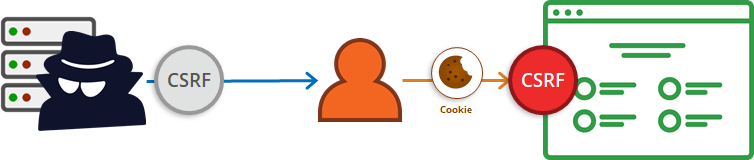
In short, this is how a CSRF attack works. In order for this to work, the attacker must know the affected site and the victim must be logged in on this site. Parameters here also play a big role, just as in the previous HPP article.
Not only GET, but also POST requests can be used during the attack.
For example, there was a CSRF vulnerability on Shopify; it has an integration with Twitter which allows the shop owners to tweet about their products, and it provides some other functions. With one of these, the user can disconnect a Twitter account from the connected shop. This can be done with a GET request which was not equipped with any protection. You can read more about it in this HackerOne report.
How can you defend against it?
The best way we can defend against CSRF is by using a unique parameter in every request.
This technique is called CSRF token and consists of two parts. The first is stored on the server side, and the user has to send the second part. Usually, we use it when we want to change something like the POST requests. So we need a unique CSRF token in every session, which we have to submit with every post request. Most websites use this as a part of a form which includes the POST parameters. The attacker cannot get the CSRF token remotely (usually) and his request doesn’t work because the CSRF token is invalid.
How can BitNinja protect against it?
Unfortunately, there is no 100% automated protection against CSRF. You could use a CSRF token in your web application which is supported by many frameworks. There may be requests from many locations that try to exploit this vulnerability. One of these is email.
BitNinja has a module which provides a defense against attacks through emails. This is the Captcha Smtp Module. We have many blocked IPs which we have captured by hidden mailbox traps. These IPs usually belong to a botnet. The module blocks emails sent to you from these sources. This module is default enabled for customers with a pro license.
Did you miss the previous parts? Catch up now:
Read the next part as well:












